专家并行策略将MoE架构下的各个“专家”子模型部署到不同的GPU或计算节点上,使其独立运算。DeepSeek团队在训练中所使用的EP策略中引入了无辅助损耗的负载平衡,通过动态偏置项实现对每个专家的训练程度的平衡。

双重流水线策略通过将一个较大数据批次分解为多个微批次,减少了计算设备的空闲时间。DeepSeek团队在传统PP策略的基础上创新性地提出并应用了Dual Pipe技术,有效地融合了前向和后向计算加速通信。
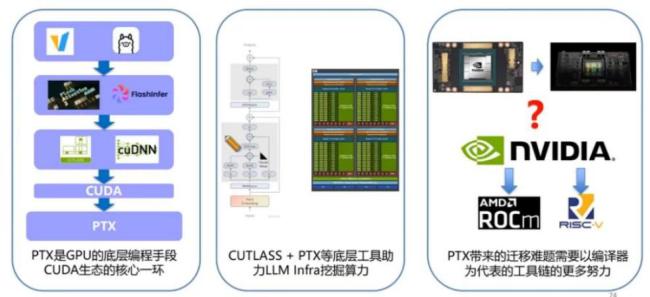
PTX代码加持为硬件工程化创新带来进一步可能。DS团队在实施硬件工程优化的过程中使用了PTX代码,显著提升了CUDA程序的可移植性和硬件调度效率。PTX指令集可以实现矩阵乘法加速、数据精度转化等多项硬件调度优化方向。



